Module Overview
A module is an executable unit that is deployed and executed on Nvidia edge devices or in the cloud on x86 servers with discrete GPUs. The module is defined in a YAML configuration file.
The module is responsible for managing every activity displayed in the following picture:
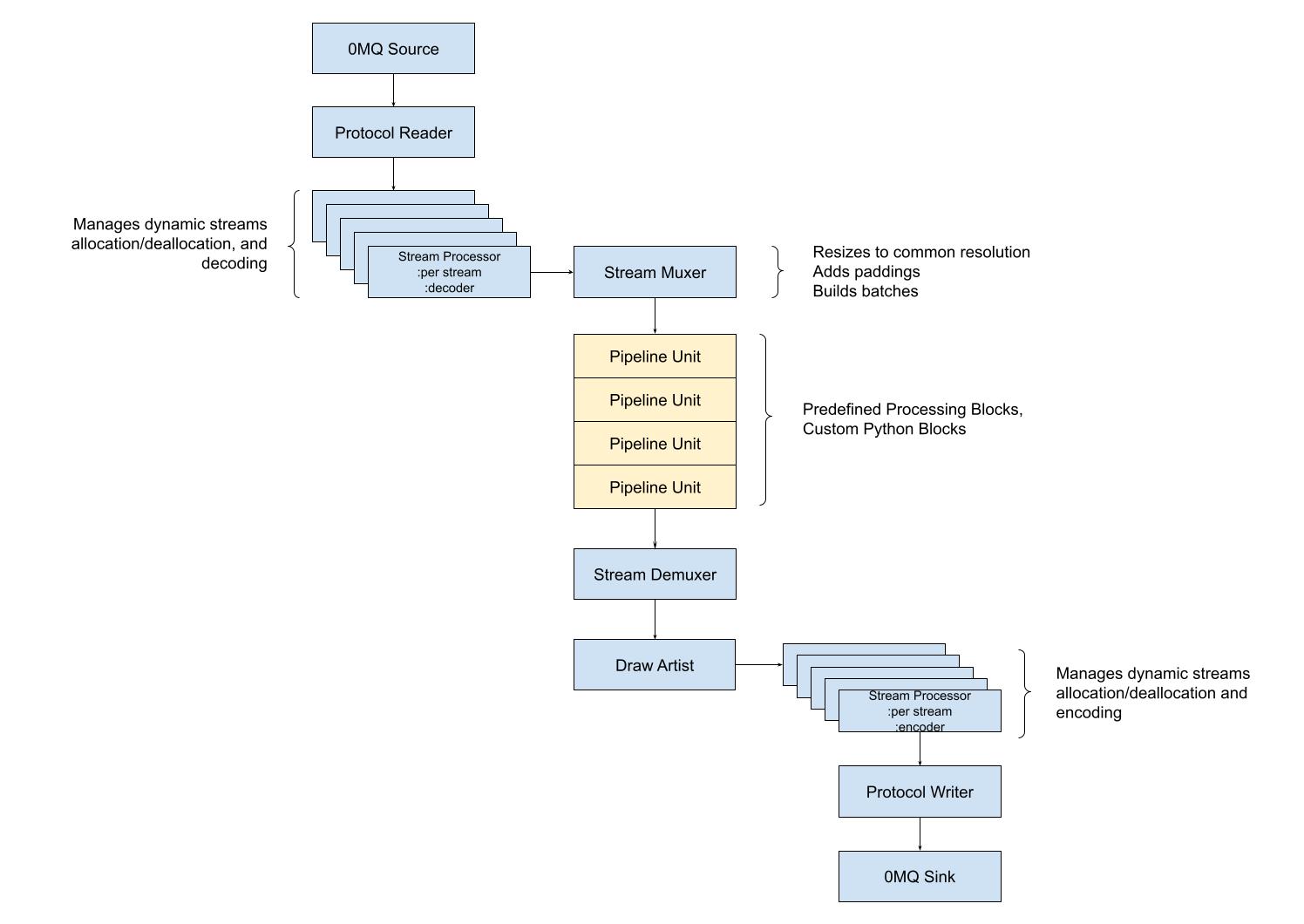
Module Runtime
Modules are executed within specially prepared docker containers. If a module does not require any additional dependencies, a base Savant docker image may be used to run it. Otherwise, a customized container must be built based on the selected base image. We provide base images for:
Nvidia DGPUs on x86 architecture
docker pull ghcr.io/insight-platform/savant-deepstream:latest
Deepstream 7.0 capable Nvidia edge devices (Jetson AGX Orin, Orin NX, Orin Nano)
docker pull ghcr.io/insight-platform/savant-deepstream-l4t:latest
The module utilizes the following directories:
/models- where compiled models are located;/downloads- where the module downloads models from remote locations;/opt/savant- where the module expects the application code root is.
Normally, you map host’s directories to the above-mentioned paths. You also can override /downloads and /models with the following parameters:
model_path: ${oc.env:MODEL_PATH, /models}
download_path: ${oc.env:DOWNLOAD_PATH, /downloads}
Module Configuration
Every module must have a name, which is an arbitrary string, the pipeline block, and parameters.
Parameters
Any number of parameters can be set in the parameters section of the module configuration file, including user-defined ones.
If you need to define a per-stream configuration, consider using external configuration options like Etcd or a database like Redis or MongoDB. Another option could be passing the required instructions in the Savant protocol with frame tags enabling precise per-frame configuration.
The following parameters are defined for a Savant module by default:
# module name, required
name: ${oc.env:MODULE_NAME}
# base module parameters
parameters:
# Logging specification string in the rust env_logger's format
# https://docs.rs/env_logger/latest/env_logger/
# The string is parsed and Python logging is set up accordingly
# e.g. "info", or "info,insight::savant::target=debug"
log_level: ${oc.env:LOGLEVEL, 'INFO'}
# the port which embedded web server binds
webserver_port: ${oc.decode:${oc.env:WEBSERVER_PORT, 8080}}
# required paths
# the path to the models directory within the module container
model_path: ${oc.env:MODEL_PATH, /models}
# the path to the downloads directory within the module container
download_path: ${oc.env:DOWNLOAD_PATH, /downloads}
# Etcd storage configuration (see savant.parameter_storage.EtcdStorageConfig).
# Etcd is used to store dynamic module parameters.
#etcd:
# # Etcd hosts to connect to
# hosts: [127.0.0.1:2379]
# # Path in Etcd to watch changes
# watch_path: savant
# pipeline processing frame parameters, use the source resolution if not set
frame:
width: ${oc.decode:${oc.env:FRAME_WIDTH, null}}
height: ${oc.decode:${oc.env:FRAME_HEIGHT, null}}
# Add paddings to the frame before processing
# padding:
# # Whether to keep paddings on the output frame
# keep: true
# left: 0
# right: 0
# top: 0
# bottom: 0
# Base value for frame parameters. All frame parameters must be divisible by this value.
# Default is 8.
# geometry_base: 8
# Custom source shaper parameters.
# The class must implement savant.base.source_shaper.BaseSourceShaper.
# shaper:
# module: samples.source_shaper_sample.custom_source_shaper
# class_name: CustomSourceShaper
# kwargs:
# foo: bar
# Maximum number of frames from the same source to process in a batch. Default is equal to batch_size.
# max_same_source_frames: 1
# Minimum desired FPS. Applied when max_same_source_frames is less than batch_size.
min_fps: ${oc.env:MIN_FPS, 30/1}
# Turn on/off limiting the maximum FPS per source.
max_fps_control: ${oc.decode:${oc.env:MAX_FPS_CONTROL, False}}
# Maximum desired FPS.
max_fps: ${oc.env:MAX_FPS, 30/1}
# pipeline output queue max size
queue_maxsize: 100
# Maximum number of parallel source streams to process.
max_parallel_streams: 64
# Configuration of the queues in GStreamer pipeline after demuxer.
# Length of the egress queue in frames (0 - no limit, default 200).
egress_queue_length: ${oc.decode:${oc.env:EGRESS_QUEUE_LENGTH, null}}
# Size of the egress queue in bytes (0 - no limit, default 10485760).
egress_queue_byte_size: ${oc.decode:${oc.env:EGRESS_QUEUE_BYTE_SIZE, null}}
# Buffer pool size configuration in DeepStream pipeline.
# Per stream buffer pool size (nvvideoconvert, output-buffers).
stream_buffer_pool_size: ${oc.decode:${oc.env:STREAM_BUFFER_POOL_SIZE, null}}
# Muxer buffer pool size (nvstreammux, buffer-pool-size).
muxer_buffer_pool_size: ${oc.decode:${oc.env:MUXER_BUFFER_POOL_SIZE, null}}
# TODO: create class for output_frame
# parameters of a frame to include in module output
# leave empty to include only metadata (no frames)
output_frame: ${json:${oc.env:OUTPUT_FRAME, null}}
# E.g.:
# output_frame:
# codec: h264
# encoder: nvenc
# encoder_params:
# iframeinterval: 25
# condition:
# tag: encode
# # Profile for software h264 encoder. Can be "baseline", "main", "high".
# # Default is "baseline".
# profile: baseline
# Codec parameters for auxiliary streams.
# Used to check whether the codec is supported by the pipeline.
# auxiliary_encoders:
# - codec: h264
# encoder: nvenc
# encoder_params:
# iframeinterval: 25
# PyFunc for drawing on frames. Should be an instance of savant.config.schema.DrawFunc.
#
# To not draw on frames leave "null".
#
# To use default class to draw on frames use an empty object ("{}")
# E.g.:
# draw_func: {}
#
# Or:
# draw_func:
# condition:
# tag: draw
#
# To use custom class to draw on frames define "module", "class_name" and "kwargs".
# E.g.:
# draw_func:
# module: custom.drawer
# class_name: CustomDrawer
# kwargs:
# color: RED
# condition:
# tag: draw
# Class to draw on frames must implement savant.deepstream.base_drawfunc.BaseNvDsDrawFunc.
draw_func: null
# When set queue elements will be added in the pipeline before and after pyfunc elements.
# It can be used to run pyfunc elements in separate threads.
# buffer_queues:
# # Length of the queue in buffers (0 - no limit), default 10.
# length: 10
# # Size of the queue in bytes (0 - no limit), default 0.
# byte_size: 0
buffer_queues: null
# Configure telemetry
# Example:
# telemetry:
# tracing:
# sampling_period: 100
# append_frame_meta_to_span: False
# root_span_name: demo-pipeline-root
# provider: opentelemetry
# # or (mutually exclusive with provider_params, high priority)
# provider_params_config: /path/to/provider_config.json
# # or (mutually exclusive with provider_params_config, low priority)
# provider_params:
# service_name: demo-pipeline
# protocol: grpc
# endpoint: "http://jaeger:4317"
# timeout: 5000 # milliseconds
# tls:
# ca: /path/to/ca.crt
# identity:
# certificate: /path/to/client.crt
# key: /path/to/client.key
# metrics:
# frame_period: 1000
# time_period: 1
# history: 100
# provider: prometheus
# provider_params:
# port: 8000
telemetry:
# Configure tracing
tracing:
# Sampling period in frames
sampling_period: ${oc.decode:${oc.env:TRACING_SAMPLING_PERIOD, 100}}
# Append frame metadata to telemetry span
append_frame_meta_to_span: ${oc.decode:${oc.env:TRACING_APPEND_FRAME_META_TO_SPAN, False}}
# Name for root span
root_span_name: ${oc.decode:${oc.env:TRACING_ROOT_SPAN_NAME, null}}
# Tracing provider name
provider: ${oc.decode:${oc.env:TRACING_PROVIDER, null}}
# Parameters for tracing provider
provider_params_config: ${oc.decode:${oc.env:TRACING_PROVIDER_PARAMS_CONFIG, null}}
provider_params: ${json:${oc.env:TRACING_PROVIDER_PARAMS, null}}
# Configure metrics
metrics:
# Output stats after every N frames
frame_period: ${oc.decode:${oc.env:METRICS_FRAME_PERIOD, 10000}}
# Output stats after every N seconds
time_period: ${oc.decode:${oc.env:METRICS_TIME_PERIOD, null}}
# How many last stats to keep in the memory
history: ${oc.decode:${oc.env:METRICS_HISTORY, 100}}
# Parameters for metrics provider
extra_labels: ${json:${oc.env:METRICS_EXTRA_LABELS, null}}
# Flag controls whether user python modules (pyfuncs and drawfuncs)
# are monitored for changes during runtime
# and reloaded in case changes are detected
dev_mode: ${oc.decode:${oc.env:DEV_MODE, False}}
# Shutdown authorization key. If set, module will shut down when it receives
# a Shutdown message with this key.
# shutdown_auth: "shutdown-auth"
Note
Any config values mentioning $-based expressions (like ${name}) are substituted with the literal defined for the name.
To access parameter values in runtime use the param_storage function:
from savant.parameter_storage import param_storage
parameter_value = param_storage()['parameter_name']
Dynamic Parameters
Savant supports module-wide dynamic parameters. Those parameters can retrieve their current values during the module execution. Currently, only Etcd is supported as a dynamic parameter source. The Etcd connection is configured in the parameters.etcd section.
etcd:
hosts: [127.0.0.1:2379]
connect_timeout: 5
watch_path: 'savant'
The dynamic parameters are available in the functions via eval_expr. Example of getting the value for savant/some_dynamic_parameter_name from Etcd:
from savant_rs.utils import eval_expr
parameter_value, _ = eval_expr('etcd("some_dynamic_parameter_name", "default_value")')
Output Queue Max Size
The queue_maxsize parameter specifies the size of the buffer located at the end of the pipeline, right before the ZeroMQ sink. The parameter may be beneficial in cases when payload metadata fluctuates between sequential frames in size significantly, causing temporary output delays. The buffer helps avoid blocking the pipeline while it has spare capacity. The default value is 100.
To configure the custom value, use:
parameters:
queue_maxsize: 100
Warning
Large values cause extra GPU/CPU memory usage.
Buffering Queues
The buffer_queues parameter is used to enable Python parallelization and enhance the performance in compute-intensive pipelines. By default, the parameter is disabled.
Read about the parameter in Python Multithreading in Savant.
Nvidia Stream Muxer and Converter Configuration
Nvidia Stream Muxer allocates a fixed number of buffers for batches. By default, it is equal to 4. Sometimes it is not enough when developer uses queues in the pipeline. Before the pipeline does not release an allocated buffer, which means that no one pipeline element works with it, stream muxer is not able to process the incoming data. Thus, the pipeline can idle. To avoid that you can use the parameter to extend the number of such buffers.
parameters:
muxer_buffer_pool_size: 16
You specify the number in batches.
Nvidia Stream Converter also allocates a fixed number of buffers for frames. By default, it is equal to 4. These frames are consumed by Nvidia Stream Muxer. To guarantee that the muxer can fill its buffers, the converter must provide enough of them.
In short, the following constraint must be satisfied:
Number_Of_Streams x Converter_Allocated_Buffers >= Batch_size x Muxer_Allocated_Buffers
E.g.,
4 streams x 8 converter buffers >= 4 frames per batch * 8 muxer buffers
32 >= 32
To configure the parameter, use:
parameters:
stream_buffer_pool_size: 32
You specify the number in frames.
Note
Remember, that buffers occupy GPU RAM, so plan them carefully.
Log Level
The log_level parameter defines the verbosity of logging for the framework. By default, it is configured as log_level: ${oc.env:LOGLEVEL, 'INFO'} which allows overriding it with the LOGLEVEL environment variable.
Note
Savant uses Rust’s env_logger-based logging configured through LOGLEVEL environment variable. Savant’s python logging is setup to accept the same logging configuration format and to pass the messages down to the underlying Rust logger. As such, for logging to be enabled, the LOGLEVEL environment variable must be set to a non-empty value. Therefore, it is recommended not to change the default log_level module configuration parameter value and to use the LOGLEVEL environment variable for logging configuration instead.
The log_level parameter value is expected to be in the Rust’s env_logger format, i.e. a comma-separated list of logging directives of the form target=level.
Possible logging levels are:
tracedebuginfowarnerror
The target is the name of the logging target, which is typically a ::-separated path to the module. All Savant’s messages are logged under the insight::savant prefix, so setting LOGLEVEL to, for example, insight::savant=info is enough to enable logging for all Savant’s modules.
Some examples of logging configuration:
info- turns on all info logginginsight::savant=info- turns on all info logging for Savant’s moduleswarn,insight::savant::custom_pyfunc=debug- turns on global warn logging and debug logging for thecustom_pyfuncmoduleinsight::savant::custom_pyfunc=debug- turns on debug logging for thecustom_pyfuncand disables all other logging sources
Output Video Stream Codec
If the output_frame section is set, Savant adds encoded video streams to sink. More information you will find in the next section Video Processing Workflow.
OpenTelemetry Configuration
The telemetry.tracing section defines the telemetry configuration. The endpoint in (telemetry.tracing.provider_params or telemetry.tracing.provider_params_config) is required when telemetry.tracing.provider is set to 'opentelemetry'.
Example:
telemetry:
tracing:
sampling_period: 100
append_frame_meta_to_span: false
root_span_name: demo-pipeline-root
provider: opentelemetry
# or (mutually exclusive with provider_params, high priority)
# use provider config file (take a look at samples/telemetry/otlp/x509_provider_config.json)
provider_params_config: /path/to/x509_provider_config.json
# or (mutually exclusive with provider_params_config, low priority)
# use provider config attributes
provider_params:
service_name: demo-pipeline
protocol: grpc
endpoint: "http://jaeger:4317"
timeout: 5000 # milliseconds
tls:
ca: /path/to/ca.crt
identity:
certificate: /path/to/client.crt
key: /path/to/client.key
Read more on OpenTelemetry in OpenTelemetry Support.
Metrics Collection Configuration
The telemetry.metrics section defines the metrics collection configuration. The port in telemetry.metrics.provider_params is required when telemetry.metrics.provider is set to 'prometheus'. labels in telemetry.metrics.provider_params defines extra labels added to the metrics.
Example:
telemetry:
metrics:
frame_period: 1000
time_period: 1
history: 100
extra_labels:
module_type: detector
DevServer Configuration
DevServer is a special module execution mode enabling change detection in custom Python code and reloading those pieces automatically without the need for container restarts.
Read more on DevServer configuration in DevServer.
Pipeline Shutdown Authentication
The shutdown_auth parameter defines a secret token which can be sent in the service shutdown message to terminate the pipeline. By default shutdown_auth is unset, and the pipeline ignores shutdown messages.
Currently, shutdown messages can be sent with Client SDK.
Pipeline
The pipeline section is where the processing steps are defined. In the section, detectors, classifiers, segmenting units, and custom Python units are placed. They are described in detail in the following sections.