Pipeline
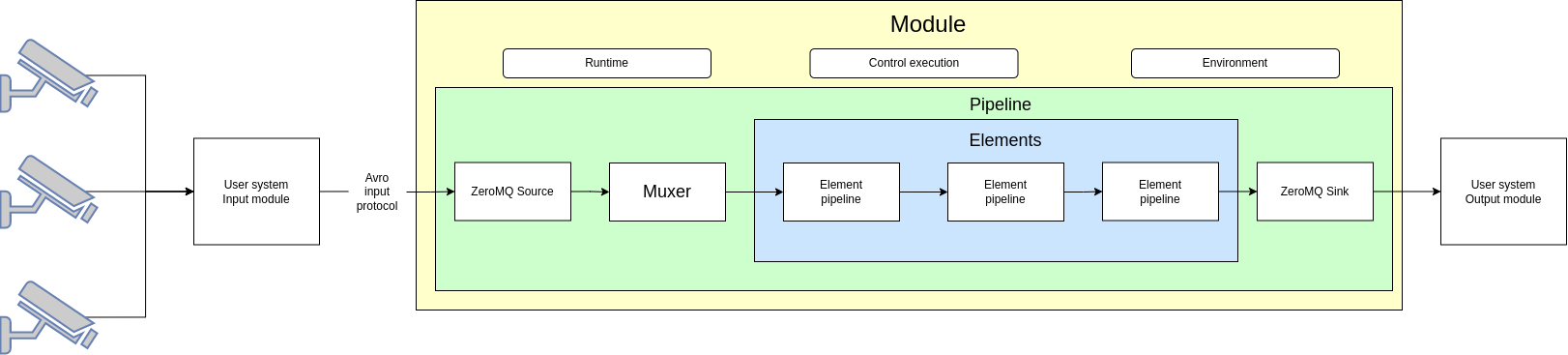
Pic 1. Video Analytics Application Scheme
A pipeline is a sequence of processing elements (units). The sequence has one input (src) and one output (sink).
Pic 1 illustrates pipeline’s place within the module: the green box represents entire pipeline and the blue box highlights a user-defined parts that are generated based on the pipeline.elements section.
Default module configuration file already defines the source and sink sections, so user don’t need to redefine them in a practical pipeline because they are derived:
# pipeline definition
pipeline:
source:
element: zeromq_source_bin
properties:
socket: ${oc.env:ZMQ_SRC_ENDPOINT}
socket_type: ${oc.env:ZMQ_SRC_TYPE, ROUTER}
bind: ${oc.decode:${oc.env:ZMQ_SRC_BIND, True}}
# Filter inbound frames by source ID.
source_id: ${oc.decode:${oc.env:SOURCE_ID, null}}
# Filter inbound frames by source ID prefix.
source_id_prefix: ${oc.decode:${oc.env:SOURCE_ID_PREFIX, null}}
# Timeout before deleting stale source (in seconds).
source_timeout: ${oc.decode:${oc.env:SOURCE_TIMEOUT, 10}}
# Interval between source eviction checks (in seconds).
source_eviction_interval: ${oc.decode:${oc.env:SOURCE_EVICTION_INTERVAL, 1}}
# Size of the source blacklist.
blacklist_size: ${oc.decode:${oc.env:SOURCE_BLACKLIST_SIZE, 1024}}
# TTL of the source blacklist in seconds.
blacklist_ttl: ${oc.decode:${oc.env:SOURCE_BLACKLIST_TTL, 10}}
# Length of the ingress queue in frames (0 - no limit, default 200).
ingress_queue_length: ${oc.decode:${oc.env:INGRESS_QUEUE_LENGTH, null}}
# Size of the ingress queue in bytes (0 - no limit, default 10485760).
ingress_queue_byte_size: ${oc.decode:${oc.env:INGRESS_QUEUE_BYTE_SIZE, null}}
# Length of the queue before decoder in frames (0 - no limit, default 5).
decoder_queue_length: ${oc.decode:${oc.env:DECODER_QUEUE_LENGTH, null}}
# Size of the queue before decoder in bytes (0 - no limit, default 10485760).
decoder_queue_byte_size: ${oc.decode:${oc.env:DECODER_QUEUE_BYTE_SIZE, null}}
# Send EOS on frame resolution change for JPEG and PNG codecs (default true).
eos_on_frame_resolution_change: ${oc.decode:${oc.env:EOS_ON_FRAME_RESOLUTION_CHANGE, null}}
# elements:
# elements should be defined here
sink:
- element: zeromq_sink
properties:
socket: ${oc.env:ZMQ_SINK_ENDPOINT}
socket_type: ${oc.env:ZMQ_SINK_TYPE, PUB}
bind: ${oc.decode:${oc.env:ZMQ_SINK_BIND, True}}
It is possible to redefine them, but the encouraged operation mode assumes the use of ZeroMQ source and sink.
When writing a module, a user normally defines only pipeline elements. All supported units are listed as follows:
detector model;
rotated detector model;
classifier model;
attribute model;
complex model;
pyfunc unit;
DeepStream tracker unit;
other DeepStream plugins (except for sinks or sources).
The units are discussed in detail in the following sections.
Note
Along with the listed units, pipeline definition may include ElementGroup nodes, which are used to introduce a condition on including the elements into the pipeline. Read more about this in the Element Groups section.
Frame Processing Workflow
A Savant pipeline is linear. It doesn’t support tree-like processing. Every frame goes from the beginning of the pipeline to the end of the pipeline. However, it doesn’t mean that every unit handles every object.
To get an idea of how the frame is processed, let us take a look at the following pseudocode reflecting the logic of operation:
# run SSD model on a whole frame, by searching its ROI
objects = inference.meta_filter(meta, frame_object=True)
if objects:
inference.run(objects, PeopleNet_detector)
inference.filter_results(configured_conditions)
inference.update_meta()
# find 'person' objects and pass them to classify the gender
objects = inference.meta_filter(meta, class='person')
if objects:
inference.run(objects, Gender_classifier)
inference.filter_results(configured_conditions)
inference.update_meta()
# again find 'person' objects and pass them to determine their age
objects = inference.meta_filter(meta, class='person')
if objects:
inference.run(objects, Age_model)
inference.filter_results(configured_conditions)
inference.update_meta()
# call pyfunc and do something with meta collected
pyfunc.run('func.name.ClassName', meta)
...
...
# draw objects selected to be drawn
objects = meta.filter(need_draw=True)
if objects:
draw_objects(objects)
So, basically every unit in the pipeline runs a unit-specific selection on metadata available. If metadata match the configured unit requirements, the unit is executed on those matched objects. Certain units like pyfunc don’t filter objects beforehand.
In other words, the pipeline doesn’t support branching directly, but it enables conditional call for units based on selection. Also, a developer can implement sophisticated “shadowing” hiding objects from a unit with a specially designed pyfunc. Our experience shows that such a functionality is enough to make complex pipelines without significant limitations.
Finally, the metadata and resulting frames are encoded in Savant protocol message and sent to the sink socket. This is done by the framework.